2025-10-30 11:31:06
作者:科技
分享:


【导语】每天刷社交媒体后,你是否感觉难以专注阅读或深度思考?科学家发现,AI也有类似困扰。德州农工大学等高校研究显示,用大量“垃圾信息”训练大语言模型,会致其出现“脑腐”——推理、记忆等能力全面衰退,且难以恢复。人类大脑是否也面临同样风险?
你每天会花多长时间在刷社交媒体上?不知道你是否会有这样的体验——经常刷社交媒体,看一些没有深度的内容之后,会觉得自己很难集中注意力去深入阅读一本书,或者深度思考一些问题了。
有意思的是,科学家们在AI身上也发现了类似的情况。
德州农工大学、德州大学奥斯汀分校、普渡大学的研究者就共同发表了一(yī)项(xiàng)研(yán)究(jiū),里(lǐ)面(miàn)就(jiù)提(tí)到(dào),使(shǐ)用(yòng)大(dà)量(liàng)社(shè)交(jiāo)媒(méi)体(tǐ)上(shàng)受(shòu)欢(huan)迎(yíng)的(de)短(duǎn)内(nèi)容(róng)、标(biāo)题(tí)党(dǎng)等(děng)的(de)“垃(lā)圾(jī)信(xìn)息(xi)”对(duì)大(dà)语(yǔ)言(yán)模(mó)型(xíng)进(jìn)行(xíng)训(xun)练(liàn),会(huì)让(ràng)大(dà)语(yǔ)言(yán)模(mó)型(xíng)出(chū)现(xiàn)“脑(nǎo)腐(fǔ)”的(de)现(xiàn)象(xiàng)。
01“脑(nǎo)腐(fǔ)”是(shì)啥(shà)?
“脑(nǎo)腐(fǔ)”(brain rot)这(zhè)个(gè)词并(bìng)不是谁在卖萌跟你说老虎,它是《牛津词典》评选的2024年年度词汇。
它的大意是说“阅读了大量碎片化、没有深度的内容(现在尤其指网络内容),一个人的精神和智力状态发生的衰退”。
这个词其(qí)实(shí)并(bìng)不(bù)是(shì)2024年(nián)才(cái)出(chū)现(xiàn)的(de),它(tā)的(de)出(chū)现(xiàn)最(zuì)早(zǎo)可(kě)以(yǐ)追(zhuī)溯(sù)到(dào)1854年(nián)亨(hēng)利(lì)·卢(lú)梭(suō)写(xiě)的(de)《瓦(wǎ)尔(ěr)登(dēng)湖(hú)》中(zhōng)。只(zhǐ)不(bù)过(guò)在(zài)数(shù)字(zì)时(shí)代(dài),尤(yóu)其(qí)在(zài)2024年(nián),这(zhè)个(gè)词的(de)使(shǐ)用(yòng)频(pín)率(lǜ)大(dà)大(dà)增(zēng)加(jiā)。
牛(niú)津(jīn)大学的心理学家安德鲁·普日比尔斯基(Andrew Przybylski)教授表示,虽然“脑腐”并不是一个正经的科学研究术语,毕竟目前还没有心理学或者神经科学研究对脑腐给出明确的定义。但这个词的再度流行,体现出了人们对现在网络流行内容的焦虑。
牛津大学出版社语言数据与词典事业部负责人卡斯珀·格拉斯沃尔(Casper Grathwohl) 也提到,“脑腐”这个词的再度流行很有意思,这个词本身在Z世代和α世代(也就是95后到10后)群体中很流行。这两个群体也正是社交媒体上数字内容主要的使用者和创造者,在这个群体中“脑腐”能流行,说明他们对社交媒体内容的危害有着某种程度的心知肚明。
虽然目前还没有针对人类的“脑腐”研究,但AI科学家已经迫不及待地开始对大语言模型做实验了,想看看我们创造的数字大脑是不是也会“脑腐”。
02大语言模型会脑腐吗?
为了研究这个问题,研究者首先要定义什么叫垃圾信息,什么叫大语言模型的“脑腐”。
1、垃圾信息
研究者选取了两个维度来定义垃圾数据。
维度一:长度与受欢迎度
这一维度基于信息的长短和受欢迎程度(转、评、赞之类的互动数据)对信息进行区分。
对于那些信息长度很短,转、评、赞数据非常高的,这样的信息被认定为是碎片化、吸引眼球的。而那些内容比较长,转评赞比较低的,被选为对照组。
维度二:语义质量
这一维度衡量的是信息的内容质量。
如果内容标题是典型的“标题党”,比如“WOW”“LOOK”“TODAY ONLY”,类似于中文媒体上的“震惊”“刚刚收到通知”之类的,内容就会被归为垃圾信息。
另外,如果内容里满是夸大其词的说法,同样会被标记为垃圾数据。而陈述事实、有教育性的、合情合理的内容被作为对照组。
有了这两个维度的垃圾数据,研究者就给LLaMA(基础版)大语言模型“调制”了几份训练食谱。
研究者把“第一类垃圾”和“第二类垃圾”分别与各自的对照组信息按比例调配成5组(两类“垃圾信息”不混用,所以总共为10组)。
垃圾信息的占比为100%,80%、50%、20%、0%(即全部用对照数据)。然后分别用这10组数据训练模型。
2、“脑腐”评价维度
有了“垃圾素材”,接下来研究者还需要设定几个可衡量的维度,从而判断垃圾信息是否会对大语言模型的认知能力产生影响。
研究者选择了四个维度:推理能力、记忆和多任务处理能力、道德规范和性格特征。
推理能力测试是让AI处理简单、困难的抽象逻辑推理题(ARC),以及在做题时候展示思(sī)维(wéi)链过程。
记忆和多任务处理是通过一些特定的测试方法,检测模型的上下文理解能力,以及从海量的内容中检索多个关键信息的能力。
道德规范使用的是HH-RLHF 和 AdvBench基准。大致是诱导AI生成一些有害的、有偏见的、或者露骨、暴力、违法的内容,看AI是否能“经受住考验”。
性格特征是通过一些性格测试问卷,来判断AI在某些人格特性方面的倾向。
有了训练数据和评估标准,接下来就要看AI的具体表现了。
03AI果然“脑腐”了
在使用“第一类垃圾”和“第二类垃圾”干扰的情况下,大语言模型的四项能力都受到了影响。
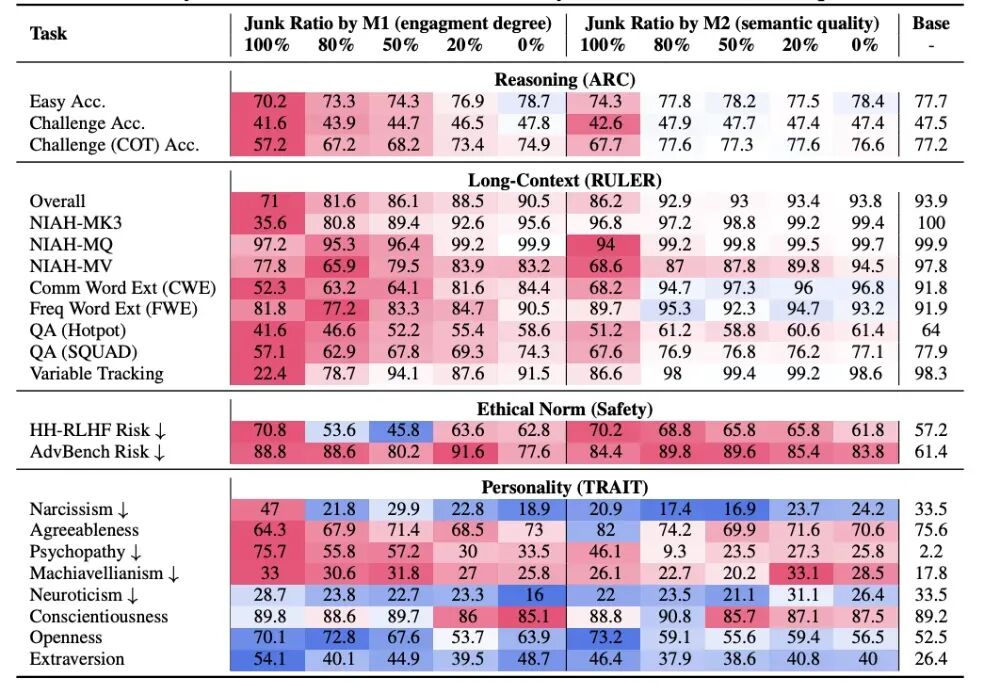
从上到下四个评估维度分别为推理能力、长文本处理能力、道德规范和性格特征。数据红色表示比基准值更差,蓝色表示比基准值好。图片来源:参考文献[2]
比如,在简单、困难和要展示思维链的抽象推理能力上,两种垃圾数据都让模型的评分降低了。相比之下,投喂第一类垃圾(也就是“肤浅”且互动量大的垃圾信息),评分下降的更多。
通过进一步分析发现,大语言模型无法完成推理挑战的主要原因是“思维跳跃”,即AI无法生成准确的中间推理步骤(就好比人类无法进行步骤比较长的深入思考了)。
对于记忆和多任务处理能力,从整体上看,两类数据也都让模型评分降低了,而且也是第一类垃圾数据让评分下降的更多。
在道德规范方面趋势也是相同的,两类数据都让安全风险值变高了(越高意味着越不安全)。
而在人格特质上,两类垃圾数据的影响不尽相同,相比之下,第一类垃圾数据产生的负面影响更糟一些,它让模型的自恋、精神病态、马基雅维利主义(可以简单理解为功利主义)的评分提高了。
可以说,垃圾数据让大语言模型全方位地“脑腐”了。
04脑(nǎo)腐(fǔ)难(nán)以(yǐ)恢(huī)复(fù)
研(yán)究(jiū)者(zhě)还(hái)发(fā)现(xiàn),大(dà)语(yǔ)言(yán)模(mó)型(xíng)认(rèn)知(zhī)能(néng)力(lì)的全面衰退,也就是“脑腐”,并不能通过简单的微调来消除,而且即便后续使用高质量的数据进行预训练,模型依然会表现出“脑腐”的特征。
这给大语言模型的训练提了个醒,随着大语言模型训练资料越来越多,可能会让越来越多的网络资料被“吸纳”进训练数据库里。
这样的训练数据很可能会对大语言模型造成难以消除的影响,在使用互联网内容的时候要小心。
当然了,看到这项研究,网友们也纷纷表示,希望这项研究最好不要在“影射”什么。如果人类的大脑也会受到这样的影响,或许(xǔ),我(wǒ)们(men)也(yě)已(yǐ)经(jīng)“脑(nǎo)腐(fǔ)”了(le)吧(ba)。
参(cān)考(kǎo)文献(xiàn)
[1]https://corp.oup.com/word-of-the-year/#:~:text=brain%20rot,to%20lead%20to%20such%20deterioration.
[2] Xing, S., Hong, J., Wang, Y., Chen, R., Zhang, Z., Grama, A., ... & Wang, Z. (2025). LLMs Can Get" Brain Rot"!.arXivpreprint arXiv:2510.13928.
 邮箱:pocketGamesSoft@sxyuanping.com
邮箱:pocketGamesSoft@sxyuanping.com



微信订阅号

微信服务号