2025-09-14 09:01:08
作者:科技
分享:


【导语】大语言模型(LLM)能否真正推理,业内争论不断。现有强化学习(RL)方法虽能提升其推理能力,但存在奖励信号弱、数据标注成本高、难以全面平衡训练效果等问题。清华大学KEG团队提出ReST-RL新范式,有效兼顾推理能力、训练效率与通用性,为LLM强化学习提供新思路,不过该方法仍存局限,有待进一步探索。

大语言模型(LLM)真的会推理吗?业内对此争论不休。
这是因为,当前的 LLM 在面对复杂代码、多步逻辑和抽象任务时依然经常“翻车”,表现出逻辑跳跃、步骤混乱、答非所问等诸多问题。
靠人教?太慢。靠奖励?信号太弱。靠验证?数据太贵。如何兼顾推理能力、训练效率与通用性,已成为业内难题。
针对这些难题,清华大学计算机科学与技术系知识工程研究室(KEG)团队提出了一种统一的 LLM 强化学习(RL)新范式——ReST-RL。该方法通过将改进的 GRPO 算法与精心设计的由价值模型(VM)辅助的测试时解码方法相结合,在提升 LLM 推理能力的同时,也兼顾了效率、稳定性与可拓展性。

实验结果显示,在 APPS、BigCodeBench 和 HumanEval 等不同级别的知名编程基准上,ReST-RL 的性能优于其他强化训练基线(如原始 GRPO 和 ReST-DPO),以及解码和验证基线(如 PRM-BoN 和 ORM-MCTS)。
这表明,ReST-RL 在增强 LLM 策略的推理能力方面潜力巨大,且为 LLM 的强化学习路径提供了新思路。
现有RL方法难实现真正推理
越来越多的研究表明,RL 能够提升 LLM 的推理能力,这一方向也成为当前的研究热点。
其中一些方法采用在线 RL,即数据采样与模型更新同步进行,代表性方法为群体相对策略优化(GRPO);其它方法则主张通过离线采样与筛选机制获取训练数据,这一范式通常被称为自训练,其代表方法是强化自训练(ReST)。尽管训练机制不同,这两类方法均能有效提升 LLM 的推理能力。
奖励模型(RMs)因其在输出验证中的重要作用,正受到越来越多的关注。已有研究表明,对 LLM 最终输出进行验证的结果奖励模型(ORM)可以提升推理准确性。多种过程奖励模型(PRMs)也被用于为中间步骤提供反馈,其验证效果优于 ORM。
然而,这些方法仍存在不足。一方面,以 GRPO 为代表的在线 RL 算法,常因奖励信号差异微弱而导致训练效果不理想。尽管部分研究尝试通过设计逐步奖励或引入简单的动态采样机制缓解该问题,但这往往带来更高的计算成本与较差的泛化能力,也使 RL 算法更为复杂。另一方面,尽管 PRMs 在验证输出方面优于 ORMs,但其训练过程通常依赖高质量的标注数据。由于数据标注成本较高,PRM 的训练数据难以扩展,从而限制了其准确性与可靠性。
有研究提出通过蒙特卡洛模拟(Monte Carlo simulations)估计并收集过程奖励。但是,这些方法难以推广至更复杂的推理任务,其对结果匹配机制的依赖也限制了适用范围。
总体来看,现有方法难以在数据采集成本、泛化能力、强化效果与(yǔ)训练效率之间实现全面平衡。
ReST-RL:训练、推理双重优化
ReST-RL 为解决训练奖励差异和 PRM 准确性问题,提供了新的可能。该方法由两个主要部分组成,分别是(shì) ReST-GRPO(基于群体相对策略优化的强化自训练方法) 和 VM-MCTS(基于价值模型的蒙特卡洛树搜索)。
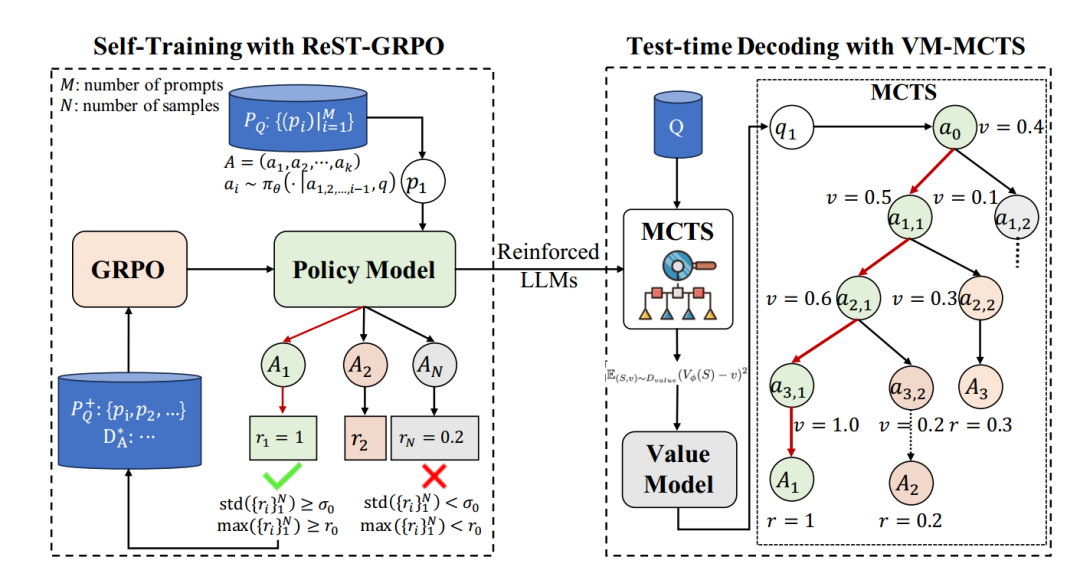
图|ReST-RL 框架
ReST-GRPO 采用优化后的 ReST 算法执行 GRPO,从而提升策略在复杂推理任务中的能力。该方法利用策略本身对训练数据进行筛选与组合,有效缓解了 GRPO 奖励失效的问题,增强了策略生成可靠推理轨迹的能力。
LLM 的输出解答及其对应的奖励中蕴含着丰富信息,反映其在目标任务域中的优势与短板,这些信息可用于过滤掉无效的训练数据。
研究团队采用标准差评估奖励的多样性。对于其所有解答的奖励标准差低于预设阈值 σ₀ 的提示语,将其从训练集中剔除。训练过程聚焦于那些高奖励的解答轨迹,并最终利用其部分解状态构建新的训练数据。
与普通 GRPO 相比,ReST-GRPO 能够显著提升训练过程中的奖励方差。
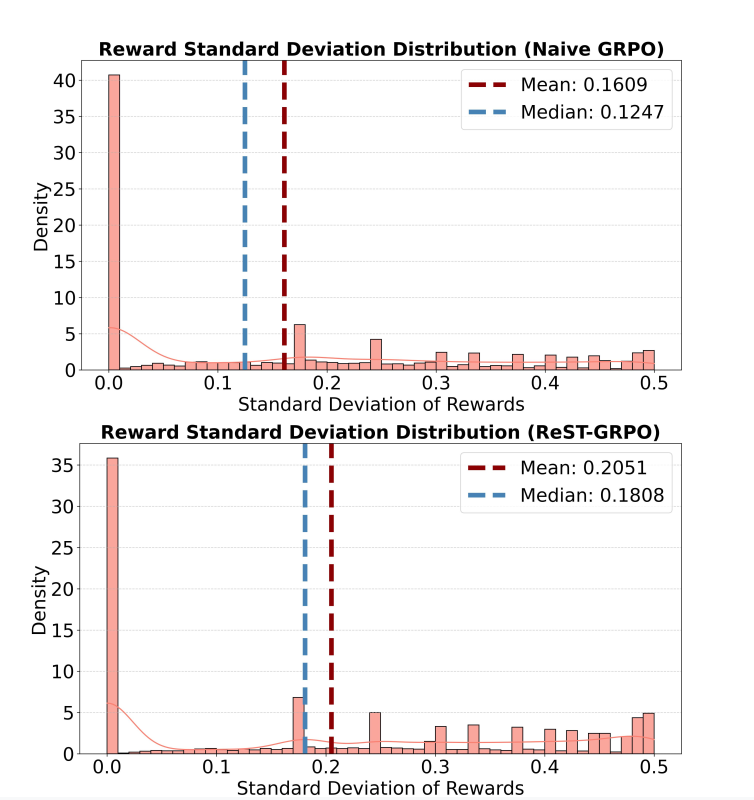
图|策略训练过程中组奖励标准差的分布。
VM-MCTS 则用于 LLM 测试阶段解码。其(qí)中(zhōng),价值模型(VM)的作用类似于 PRM,不仅提供验证信号,还能引导 LLM 策略探索更有潜力的推理路径。VM 的价值目标用于评估包含最后一步在内的整个部分状态,而非单一动作或步骤。它自然地反映了(le)策(cè)略(è)从(cóng)当(dāng)前(qián)局部状态到达高奖励终态zan的潜力,可在解码过程中为策略提供辅助。
在为 VM 收集训练数据时,他们采用 MCTS 方法,以在探索不同推理路径和利用高潜力中间状态之间取得平衡。一旦收集到足够的价值目标数据,即可训练 VM 去预测各类状态的价值。
使用该方法训练得到的 VM 能够准确预测当前策略下部分状态的预期奖励。该算法通过价值估计来决定应当探索和解码哪些路径,从而提高搜索的效率与准确性。
研究团队通过大量编码问题实验,验证了所提出 RL 范式及其各组成部分的有效性,证明 ReST-RL 不仅能够增强 LLM 策略的推理能力,同时在效率、成本和泛化性等方面实现了较好的平衡。
结果表明,ReST-RL 及其组件在性能上全面优于其他强化学习基线方法(如原始 GRPO 和 ReST-DPO),以及解码与验证基线方法(如 PRM-BoN 和 ORM-MCTS)。
在相同训练步数下进行测试对比表明,ReST-GRPO 相较于原始 GRPO 和 DAPO 拥有更高的训练效率。
在解码验证预算相同的条件下,VM-MCTS 及其 VM 在准确性方面,优于此前基于公开数据训练的 Math-Shepherd 风格 PRM 或 ORM。
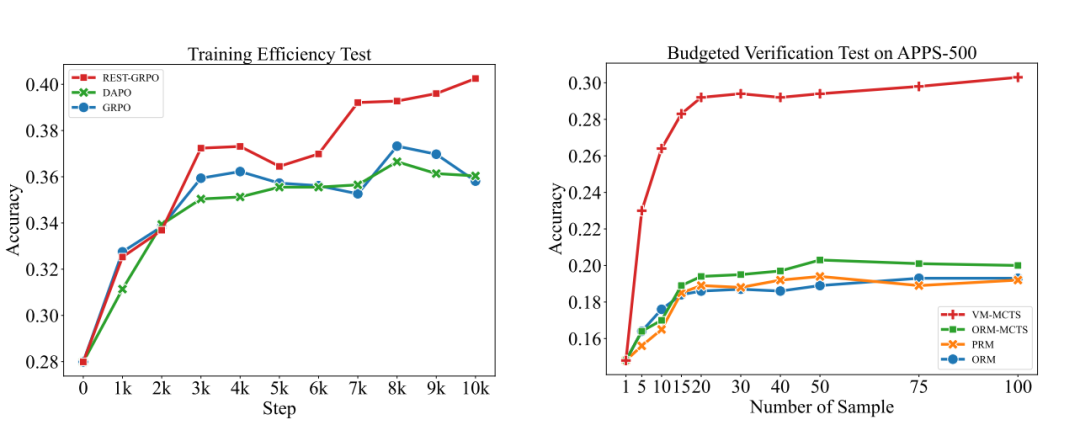
图|训练效率与预算内验证能力的测试。
局限与未来方向
尽管各(gè)项(xiàng)实(shí)验(yàn)证(zhèng)明(míng)了(le) ReST-RL 的有效性,但该方法仍存在一定的局限性。
例如,研究尚未在代码推理以外的任务(如数学推理和常识推理)中对其进(jìn)行(xíng)验(yàn)证。虽然该方法框架并不局限于代码任务,但在其他场景下的应用可能需要重新设计合适的奖励机制和实验超参数。
另外,部分实验设置对最终结果的具体影响也尚未得到系统性分析。
研究团队还(hái)表(biǎo)示(shì),价(jià)值(zhí)模(mó)型(xíng)在(zài)域外(wài)任(rèn)务(wu)中(zhōng)的(de)准(zhǔn)确(què)性(xìng)仍(réng)缺(quē)乏(fá)充(chōng)分(fēn)研(yán)究(jiū),后(hòu)续(xù)工(gōng)作(zuò)将(jiāng)进(jìn)一(yī)步(bù)探(tàn)索(suǒ) ReST-RL 在(zài)更(gèng)广(guǎng)泛(fàn)任(rèn)务(wu)中(zhōng)的(de)泛(fàn)化(huà)能(néng)力(lì)。
封(fēng)面(miàn)图(tú)为(wèi)版(bǎn)权(quán)图(tú)库(kù)图(tú)片(piàn),转(zhuǎn)载(zài)使(shǐ)用(yòng)可(kě)能(néng)引(yǐn)发(fā)版(bǎn)权(quán)纠(jiū)纷(fēn)
 邮箱:pocketGamesSoft@sxyuanping.com
邮箱:pocketGamesSoft@sxyuanping.com



微信订阅号

微信服务号